

LLaMa và Bard đâu mới là đối trọng của ChatGPT?
25/3/202317phút đọcChatGPT
LLaMA
Bard
Xử lý ngôn ngữ tự nhiên (tiếng anh: Natural Language Processing gọi tắt là NLP) đang là một trong những chủ đề “nóng bỏng” nhất của lĩnh vực khoa học máy tính, điều này được thể hiện qua việc các công ty công nghệ trên thế giới đã không ngần ngại đầu tư rất nhiều tiền để nghiên cứu phát triển các ứng dụng mới trong lĩnh vực này. Các ông lớn của ngành công nghệ trên thế giới cũng không nằm ngoài cuộc chơi này, nổi bật hơn cả là 2 gã không lồ cùng đến từ xứ sở cờ hoa là Google và Microsoft.
Quay ngược về quá khứ, cuộc chiến này đã bắt đầu từ cuối năm 2018 nhóm nghiên cứu của Google đã giới thiệu với cộng đồng về mô hình ngôn ngữ BERT với mục đích cải thiện kết quả tìm kiếm của công cụ Google Search thông qua việc hiểu ngôn ngữ tự nhiên. Điểm nổi bật của mô hình BERT là khả năng huấn luyện mạng thần kinh nhân tạo để mô hình học được các đặc trưng từ dữ liệu thô thay vì dựa nhiều vào kỹ thuật thống kê như các cách tiếp cận trước đó. Đầu năm 2019, tổ chức nghiên cứu có tên OpenAI được sự hậu thuẫn của tập đoàn Microsoft đã công bố mô hình ngôn ngữ có tên GPT-2 mà theo các tác giả đây là mô hình ngôn ngữ lớn nhất tại thời điểm ra mắt với hơn 1 tỷ tham số huấn luyện mô hình học sâu. Tuy nhiên, đội ngũ nghiên cứu của Google đã không tiếp tục phát triển các mô hình BERT trong khi OpenAI vẫn tập trung chất xám vào các thế hệ tiếp theo của GPT mà đỉnh điểm là GPT-3 (2020) với hơn 175 tỷ tham số.
Tưởng chừng như cuộc chiến này đã ngã ngũ khi OpenAI vẫn liên tục phát triển các mô hình GPT và ứng dụng của nó đặc biệt là sự ra đời của ChatGPT đang “làm mưa làm gió”, thì mới đây Google vừa công bố Bard - một chatbot đối thoại mà ChatGPT cần dè chừng. Ngoài sự đe doạ đến từ Google, gần đây CEO Mark Zuckerberg của Meta (công ty mẹ của mạng xã hội Facebook) vừa tiết lộ đội ngũ nghiên cứu của công ty này cũng đang cố gắng tham gia vào cuộc chiến này với phát súng đầu tiên là mô hình ngôn ngữ lớn LLaMA, mô hình và dữ liệu của công việc này hướng đến xây dựng mã nguồn mở nhằm phục vụ cộng đồng nghiên cứu. LLaMA được phát triển với mục tiêu ban đầu là giải quyết đa tác vụ của lĩnh vực NLP, đối thủ mà LLaMA hướng đến là chính là các mô hình GPT. Vì là mã nguồn mở, nên ngay lập tự đã có một đại diện đến từ cộng đồng là NebulyAI đã thực hiện tinh chỉnh thành công mô hình LLaMA với khung làm việc RLHF tương tự như cách mà GPT chuyển mình thành ChatGPT, công việc này được NebulyAI gọi là ChatLLaMA.
Cộng đồng mạng Việt Nam có câu: “Hổ không gầm 🐶 tưởng rừng xanh vô chủ”, trong trường hợp này quả thật không sai. Bài viết này sẽ gửi đến bạn đọc một phân tích tổng quan về hai đối thủ “xứng tầm” của ChatGPT hiện tại là Google Bard và ChatLLaMA. Ngoài ra, chúng tôi cũng đã thực hiện một bài viết về công nghệ xây dựng nên ChatGPT, bạn đọc có thể truy cập bài viết tại đây để hiểu rõ hơn một số khái niệm được sử dụng ở bài viết này, đặc biệt là khung làm việc RLHF.
1. Google Bard
Như chúng ta đều biết, Google được xem là một trong các công ty tiên phong khai thác ứng dụng Xử lý ngôn ngữ tự nhiên (NLP) thông qua 2 ứng dụng phổ biến mà chắc hẳn ai trong chúng ta đều ít nhất đã sử dụng qua một lần hoặc rất nhiều lần đó là công cụ tìm kiếm (Google Search) và công cụ dịch đa ngôn ngữ (Google Translation). Việc sở hữu 2 công cụ trên là nền tảng vững chắc để Google đầu tư mạnh mẽ vào phát triển các ứng dụng liên quan Xử lý ngôn ngữ tự nhiên. Quay ngược thời gian 2 năm về trước, Google đã công bố một nghiên cứu có tên là Mô hình ngôn ngữ cho các ứng dụng đối thoại (tiếng anh: Language Model for Dialogue Applications gọi tắt là LaMDA), đây có thể xem là động lực để các nhà nghiên cứu kế thừa và phát triển thành công cụ chatbot Google Bard. Do đó trong phần này của bài viết, chúng tôi sẽ tập trung phân tích mô hình LaMDA.
Kể từ khi ra mắt vào năm 2017, kiến trúc Transformer đã trở thành xương sống cho hầu hết các ứng dụng liên quan đến ngôn ngữ tự nhiên, đây cũng là một trong những thành quả nghiên cứu đến từ đội ngũ của Google. Mô hình LaMDA cũng dựa trên kiến trúc Transformer, nhưng được phát triển theo hướng tập trung vào ứng dụng đối thoại. Sau khi được xây dựng, LaMDA bao gồm 137 tỷ tham số và được tiền huấn luyện trên 1.56 nghìn tỷ từ (words) thuộc dữ liệu hội thoại công khai và văn bản web. Mục tiêu ban đầu của các nhà phát triển là tập trung vào cải thiện chất lượng các cuộc hội thoại được sinh ra, trong khi đó lại không tính đến các thách thức về an toàn và xác thực thông tin. Để giải quyết hạn chế này, mô hình LaMDA được tinh chỉnh với dữ liệu được hướng dẫn xem như các chú thích, đồng thời cho phép mô hình tra cứu nguồn kiến thức bên ngoài để cải thiện độ tin cậy của thông tin. Đối với thách thức về sự an toàn của các phản hồi của mô hình được đánh giá dựa trên sự phù hợp với từ người dùng, ví dụ như ngăn chặn các thông tin có hại và thiên vị. Còn với thách thức về độ xác thực của thông tin, thông qua việc sử dụng một số liệu đo groundedness để đánh giá tính chân thực, điều này cho phép mô hình tạo ra các phản hồi có thông tin chính xác với các nguồn được tham khảo, thay vì những phản hồi “có vẻ” hợp lý.
Các nhà phát triển LaMDA đã mô tả quá trình huấn luyện mô hình bao gồm 2 bước: tiền huấn luyện và tinh chỉnh.
1.1 Tiền huấn luyện:
Mô hình được tiền huấn luyện để dự đoán từ tiếp theo trong một câu. Đối với giai đoạn đào tạo trước, các nhà phát triển đã tạo tập dữ liệu gồm bao gồm 2.97 tỷ tài liệu, 1.12 tỷ hộp thoại và 13.39 tỷ lời thoại, tổng cộng là 1.56 nghìn tỷ. Hơn 90% bộ dữ liệu bằng tiếng Anh, tất cả đều đến từ nguồn dữ liệu công khai trên internet. Tập dữ liệu này sau đó được mã hóa (biến thành một chuỗi ký tự để tạo câu) thành mã thông báo bao gồm 2.81 nghìn tỷ để tiền huấn luyện mô hình sinh ngôn ngữ. Hình 1 minh hoạ quá trình dự đoán thành phần tiếp theo trong câu trong quá trình tiền huấn luyện mô hình sinh ngôn ngữ của LaMDA.

Hình 1. Minh hoạ tác vụ dự đoán thành phần tiếp theo trong câu trong quá trình tiền huấn luyện mô hình LaMDA. Nguồn: LaMDA: Language Models for Dialog Applications
1.2 Tinh chỉnh mô hình
Trong giai đoạn tinh chỉnh, mô hình LaMDA được huấn luyện để thực hiện kết hợp giữa nhiệm vụ sinh câu phản hồi và phân loại chúng. Nói cách khác, các câu phản hồi bằng ngôn ngữ tự nhiên được sinh ra cho các ngữ cảnh nhất định đồng thời phân loại chúng dựa trên mức độ an toàn và chất lượng. Điều này dẫn đến việc phải xây dựng và huấn luyện một mô hình đa tác vụ có khả năng thực hiện cả hai tác vụ trên.
Ở tác vụ sinh câu phản hồi, LaMDA được đào tạo để sinh ra câu phản hồi tiếp theo dựa trên tập dữ liệu giới hạn trong phạm vi hộp thoại qua lại giữa người và tác nhân (mô hình). Trong khi đó, bộ phân loại của LaMDA được đào tạo để dự đoán điểm số An toàn và Chất lượng cho phản hồi trong ngữ cảnh sử dụng dữ liệu được chú thích. Trong một hộp thoại, bộ sinh văn bản của LaMDA tạo ra một số phản hồi được xem là các đề xuất dựa trên bối cảnh hộp thoại nhiều lượt, sau đó mô-đun phân loại LaMDA dự đoán điểm Chất lượng và An toàn cho từng đề xuất phản hồi và những phản hồi có điểm An toàn thấp sẽ bị lọc ra. Các đề xuất phản hồi còn lại được xếp hạng lại dựa trên điểm Chất lượng của chúng, cuối cùng câu phản hồi có điểm đánh giá tốt nhất được chọn để phản hồi cho người dùng. Ngoài ra, các nhà phát triển cũng sử dụng bộ phân loại LaMDA để lọc dữ liệu trong quá trình huấn luyện tác vụ sinh văn bản, việc này giúp tăng số lượng các đề xuất phản hồi chất lượng cao.
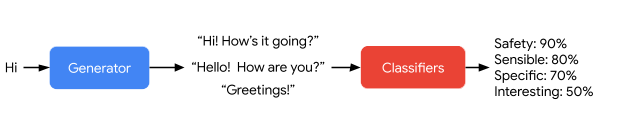
Hình 2. Minh hoạ quá trình tinh chỉnh chất lượng các câu phản hồi của mô hình LaMDA. Nguồn: LaMDA: Language Models for Dialog Applications.
1.3 Đánh giá mô hình
Các nhà phát triển đánh giá LaMDA qua từng tác vụ của mô hình bao gồm: phản hồi sinh ra từ mô hình tiền huấn luyện, mô hình tinh chỉnh và cả những đánh giá từ người thật. Ngoài ra, họ còn yêu cầu một nhóm người đánh giá những phản hồi này dựa trên các chỉ số Chất lượng, An toàn và Căn cứ. Các kết quả thực nghiệm cho thấy LaMDA vượt trội hơn đáng kể so với mô hình được đào tạo trước. Các chỉ số chất lượng (Độ nhạy, Độ đặc hiệu và Độ thú vị) thường cải thiện khi số lượng tham số mô hình tăng lên, có hoặc không có tinh chỉnh. Mặc dù chỉ riêng việc mở rộng kích thước mô hình dường như không ảnh hưởng đến độ an toàn, nhưng việc tinh chỉnh sẽ giúp cải thiện chỉ số này. Khi kích thước mô hình tăng lên, groundedness được cải thiện, có lẽ vì các mô hình lớn hơn có thể lưu trữ nhiều kiến thức không phổ biến hơn. Việc tinh chỉnh cho phép mô hình truy cập các nguồn kiến thức bên ngoài, do đó giảm bớt một số gánh nặng ghi nhớ thông tin. Mặc dù khoảng cách về chất lượng so với mức độ con người có thể được thu hẹp bằng cách tinh chỉnh, nhưng hiệu suất của mô hình vẫn thấp hơn mức con người về độ an toàn và thông tin sự thật.
2. Chat LLaMA
Nếu bạn đọc đã thử sử dụng qua ChatGPT, bạn sẽ nhận thấy rằng chúng cực kỳ hiệu quả và có thể tạo ra những mẩu thông tin cực kỳ tuyệt vời đến mức khó có thể phân biệt đâu là do ChatGPT viết và đâu là do con người viết. ChatGPT đã thể hiện tính linh hoạt của mình bằng cách thực hiện nhiều nhiệm vụ khác nhau, từ viết bài luận, lập danh sách mua hàng tạp hóa đến bắt chước quá trình suy nghĩ của những người nổi tiếng. Mặc dù ChatGPT vẫn đang trong quá trình hoàn thiện và còn nhiều hạn chế, nhưng hiệu suất của nó là rất ấn tượng. Tuy nhiên các nghiên cứu và nguồn dữ liệu được sử dụng đằng sau ChatGPT vẫn được giữ kín dẫn đến những thách thức cố hữu về việc chia sẻ công nghệ trong cộng đồng. Mô hình ngôn ngữ LLaMA và ChatLLaMA được ra đời như một cơn mưa rào giữa nắng hạn. Công việc này bắt đầu với LLaMA - một dự án về mô hình ngôn ngữ lớn được phát triển bởi Meta AI, dự án này ban đầu là mã nguồn mở nhằm mục đích giúp các nhà nghiên cứu, kỹ sư và nhà khoa học triển khai việc sử dụng AI để hỗ trợ công việc của họ. Gần đây với một nhóm các nhà nghiên cứu trong cộng đồng NLP đã phát triển thành công ChatLLaMA thông qua việc triển khai mô hình mã nguồn mở LLaMA với việc tinh chỉnh các câu phản hồi theo phong cách của ChatGPT để bất kỳ ai cũng có thể phát triển một dự án tương tự.
Trong khi hầu hết các mô hình ngôn ngữ lớn hiện nay đều không công khai dữ liệu huấn luyện, điển hình là GPT-3 , thì mô hình LLaMA được giới thiệu là chỉ sử dụng các nguồn dữ liệu có sẵn công khai, điều này giúp cho mô hình LLaMA trở nên tương thích với mã nguồn mở nhằm phục vụ cộng đồng. Dữ liệu huấn luyện của LLaMA đến từ nhiều nguồn kết hợp, bao gồm: CommonCrawl (67%), C4(15%), Github (4.5%), Wikipedia (4.5%), Books (4.5%), ArXiv (2.5%), và StackExchange (2.0%). Các dữ liệu này được tokenize hoá bởi thuật toán BPE (Byte-Pair Encoding), tổng cộng có 1.4 tỷ token dùng để huấn luyện mô hình. Trong bài báo giới thiệu mô hình LLaMA, các tác giả đã tuyên bố mô hình đề xuất với 13 nghìn tỷ tham số huấn luyện đã vượt trội hơn mô hình GPT-3 (175 nghìn tỷ) về các chỉ số điểm chuẩn đánh giá.
Cũng dựa trên kiến trúc Transformer như các mô hình ngôn ngữ đang mang lại hiệu suất cao trong lĩnh vực NLP hiện nay, tuy nhiên các nhà phát triển đã thực hiện một số điều chỉnh để khiến LLaMA trở nên vượt trội hơn, phạm vi của bài viết là phân tích các mô hình giải quyết tác vụ đối thoại chúng tôi chỉ lướt qua một số điểm nổi bật trong quá trình tiền huấn luyện mô hình đa tác vụ LLaMA:
- Tiền chuẩn hoá (tiếng anh: Pre-normalization) để cải thiện sự ổn định trong quá trình huấn luyện. Sự chuẩn hoá được thực hiện tại mỗi lớp phụ của kiến trúc Transformer.
- Thay thế hàm kích hoạt ReLU bằng một hàm có tên SwiGLU được đề xuất trong nghiên cứu PaLM.
- Xoay véc-tơ nhúng bằng việc thay thế hoàn toàn các khối tính toán thông tin vị trí nhúng (tiếng anh: positional embeddings) bằng một mô-đun xoay vị trí nhúng (tiếng anh: rotary positional embeddings gọi tắt RoPE) tại mỗi lớp của mạng.
Tương tự với các công việc hướng mô hình ngôn ngữ đa tác vụ sang tập trung vào một nhiệm vụ duy nhất (GPT → ChatGPT), ChatLLaMA cũng dựa trên ý tưởng này bằng việc tinh chỉnh mô hình sinh ngôn ngữ LLaMA dựa trên khung làm việc Học tăng cường từ phản hồi người dùng (tiếng anh: Reinforcement Learning from Human Feedback gọi tắt RLHF). Đây được xem là mã nguồn mở đầu tiên thực hiện tinh chỉnh mô hình ngôn ngữ LLaMA dựa trên RLHF.
Một số điểm nổi bật của ChatLLaMA:
- Đây là mã nguồn mở hoàn toàn, thực hiện huấn luyện một dịch vụ chatbot tương tự ChatGPT dựa trên một mô hình ngôn ngữ được tiền huấn luyện LLaMA.
- So sánh với phiên bản gốc ChatGPT, quá trình huấn luyện và quá trình suy luận trên 1 GPU chỉ ra rằng ChatLLaMA nhanh hơn và tiết kiệm hơn bởi việc dựa trên một kiến trúc mô hình ngôn ngữ nhỏ hơn.
- ChatLLaMA được hỗ trợ trong quá trình xây dựng và phát triển bởi DeepSpeed ZERO để tăng tốc quá trình tinh chỉnh.
- Thư viện ChatLLaMA cũng hỗ trợ tất cả phiên bản kiến trúc của mô hình LLaMA gồm 7B, 13B, 33B, 65B tham số huấn luyện. Do đó, các nhà nghiên cứu trong cộng đồng có thể tinh chỉnh mô hình theo sở thích cũng như theo thời gian huấn luyện và chất lượng kết quả mong muốn.
3. Lời kết
Bài viết này đã phân tích công nghệ xây dựng nên hai đối thủ tiềm năng đang đe doạ vị thế độc tôn của ChatGPT hiện nay đó là Google Bard và ChatLLaMA. Ở đó, ChatLLaMA sử dụng cùng một mô-tuýp để xây dựng nên một chatbot từ một mô hình ngôn ngữ đa tác vụ là thông qua quá trình tinh chỉnh sử dụng khung làm việc RLHF. Đối với Google Bard, quá trình huấn luyện vẫn diễn ra theo 2 giai đoạn là tiền huấn luyện và tinh chỉnh để đảm bảo chất lượng các câu phản hồi được tốt hơn, tuy nhiên cơ chế quản lý quản chất lượng các câu phản hồi của Google Bard nhìn chung khá thủ công so với việc ứng dụng phương pháp Học tăng cường ở RLHF. Điểm nổi bật của Google Bard có thể kể đến là khả năng xác thực các thông tin sự thật bằng việc kiểm tra thông tin với các nguồn dữ liệu bên ngoài.
Phạm vi bài viết không chỉ ra một mô hình nào đang vượt trội so với các mô hình còn lại, tuy nhiên có thể thấy tiềm năng phát triển của ChatLLaMA là vô cùng lớn bởi các yếu tố: mô hình tiền huấn luyện nhỏ hơn GPT dẫn dến quá trình huấn luyện và suy luận nhanh hơn, nguồn dữ liệu công khai có thể quản lý được, và đặc biệt là mã nguồn mở được đóng góp liên tục hằng ngày hằng giờ bởi cộng đồng NLP trên toàn thế giới.
4. Tài liệu tham khảo
Devlin, Jacob et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” ArXiv abs/1810.04805 (2019).
Brown, Tom B. et al. “Language Models are Few-Shot Learners.” ArXiv abs/2005.14165 (2020).
Hugo, T. et al. “LLaMA: Open and Efficient Foundation Language Models.” ArXiv abs/2302.13971 (2023).
Thoppilan, Romal et al. “LaMDA: Language Models for Dialog Applications.” ArXiv abs/2201.08239 (2022).